Swift Neural Network Tutorial

The goal of this post is to show how to build, learn and run probably one of the simplest Neural Networks, which will compute the XOR function.
This is my second post about Artificial Intelligence and Machine Learning with Swift. If you would like to read more about Genetic Algorithms, please click here.
1. Introduction
As previously, the aim of this post is not to introduce Neural Networks as a topic in general, as it has been done by many much better teachers than me. If you are new to this topic, please devote some time to read the following introduction below, so you will be able to better understand what’s going on in the later parts of this post: Intro to Neural Networks
2. XOR Function
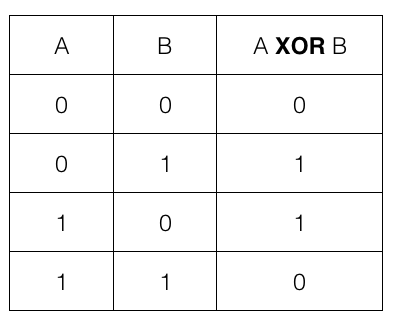
Why would we like to have an NN to compute XOR if we can do this with a single line of code? Because XOR is really simple, it’s also well known for all developers, so we don’t have to devote more time for problem analysis. We can just focus on the process of creating, learning and running NN. As a reference, below is a table with possible inputs and outputs for the XOR function:
3. Network
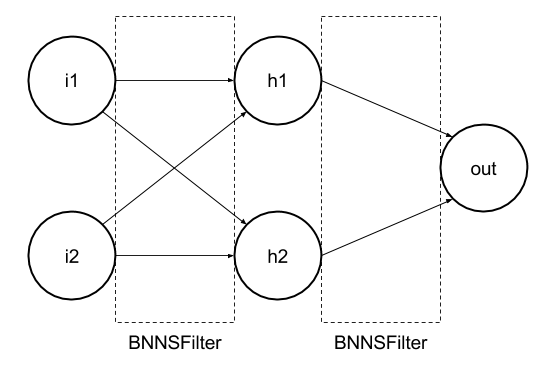
A Neural Network is a system built of connected “neurons” (see the circles on below scheme), which are used to store information, which is then processed and propagated to other neurons (in this case to neurons in a different layer). Connections (arrays on a scheme) between neurons have parameters called weights, these parameters can be adjusted, so the results of information processing are more accurate, this process is called learning.
We will build a very simple neural network. That means we will have 1 input layer, 1 output layer, and there will be also 1 hidden layer between them, as on the scheme below:
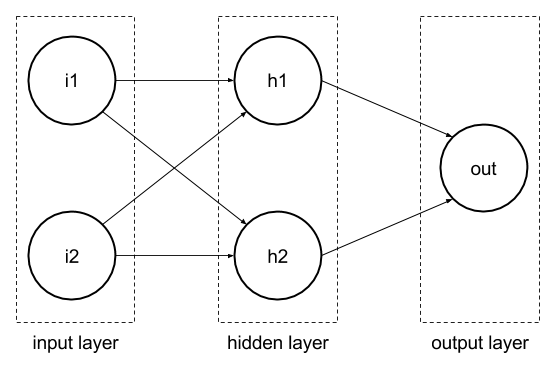
The XOR function has 2 input variables and produces 1 result, this is why the input layer has 2 neurons and the output layer only has 1. The number of neurons in the hidden layer is basically unlimited, but for a simple XOR, 2 it’s more than enough. So, we know what our inputs will be for i1 and i2, but what happens next?
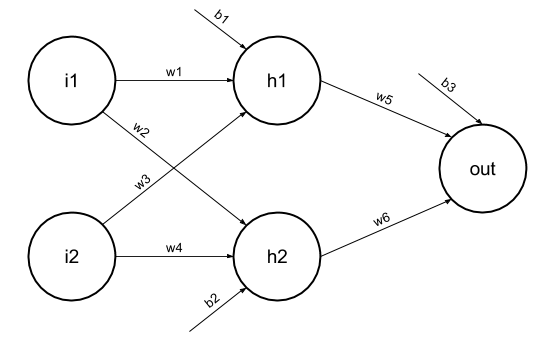
As can be seen in the above scheme, we can count the values of h1 and h2, based on i1 and i2. The formula is pretty simple:
h1 = i1*w1 + i2*w3 + b1
h2 = i1*w2 + i2*w4 + b2
You probably noticed 3 additional parameters, which appeared on the scheme: b1, b2 and b3 are called bias parameters. But what do they do, and why do we need them? There is an awesome explanation already on StackOverflow, so I will just refer to it: The role of bias in neural networks.
With h1 and h2 ready, the network is now able to find out final answer, according to this formula:
out = h1*w5 + h2*w6 + b3
Ok, I believe it’s now pretty obvious for everyone how the neural network works, but the question is, how do we find all the weight and bias parameters? The answer is pretty simple: learn the network.
4. Training
There are many ways of training a neural network, there are also many tools available to do this, but for those with less experience (like me), there is one relatively easy tool to understand and use – TensorFlow. TensorFlow is an open source software library for machine learning developed by Google. It has an API for Python and C++, but in this post, I will focus on Python only.
If you have never used TensorFlow, please download and install it first. It’s also worth reading the ‘Getting Started’ section, which explains all basic aspects of network training in TensorFlow.
Time to write some code:
import tensorflow as tf inputStream = tf.placeholder(tf.float32, shape=[4,2]) inputWages = tf.Variable(tf.random_uniform([2,2], -1, 1)) inputBiases = tf.Variable(tf.zeros([2])) outputStream = tf.placeholder(tf.float32, shape=[4,1]) outputWages = tf.Variable(tf.random_uniform([2,1], -1, 1)) outputBiases = tf.Variable(tf.zeros([1]))
We start with importing the TensorFlow library and defining variables, which will store wages and biases:
inputWages contains w1,w2,w3,w4
inputBiases contains b1,b2
outputWages contains w5,w6
outputBiases contains b3
We also defined 2 placeholders to store training data. TensorFlow will fill them with proper params during the training. But, if all the parameters are changed during the learning process, why do we use placeholders and variables? In fact, there is a significant difference between them, variables require initial values (we initially set them to zero), while placeholders are just allocated as storage for unknown data. In other words, it means that placeholder values can be read from things like an external file in runtime (a very common case), while variables must have defined values before the script will run.
inputTrainingData = [[0,0],[0,1],[1,0],[1,1]] outputTrainingData = [[0],[1],[1],[0]]
I strongly believe that Input data, in the case of the XOR function doesn’t demand further explanation.
hiddenNeuronsFormula = tf.sigmoid(tf.matmul(inputStream, inputWages) + inputBiases) outputNeuronFormula = tf.sigmoid(tf.matmul(hiddenNeuronsFormula, outputWages) + outputBiases)
Both inputNeuronsFormula and outputNeuronsFormula can be read from scheme 2, but there are 2 additional operations here:
matmul – is the matrix multiplication function,
sigmoid – is the sigmoid calculation function.
cost = tf.reduce_mean(( (outputStream * tf.log(outputNeuronFormula)) + ((1 - outputStream) * tf.log(1.0 - outputNeuronFormula)) ) * -1)
This is the formula to count cost (with the value showing how far our current solution is from the desired one).
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
TensorFlow offers few methods of neural network training. We will use the most popular and simplest: gradient descent (more details here). The aim of learning this process is for adjusting weights and biases so that the cost is as small as possible.
init = tf.global_variables_initializer()
In TensorFlow, variables are not initialized when we call the tf.Variable. To initialize all the variables in a TensorFlow program, we must explicitly call a special operation:
sess = tf.Session() sess.run(init)
It is important to realize that init is a handle to the TensorFlow sub-graph that initializes all the global variables. Until we call sess.run, the variables are uninitialized. The above code creates a Session object and then invokes its run method to prepare everything for the learning process.
for i in range(10000):
sess.run(train_step, feed_dict={inputStream: inputTrainingData, outputStream: outputTrainingData})
This simple loop tries to learn out NN 10000 times, based on input learning data and using the expected output as feedback for the gradient descent algorithm.
print('Input wages: ', sess.run(inputWages))
print('Input biases: ', sess.run(inputBiases))
print('Output wages: ', sess.run(outputWages))
print('Output biases: ', sess.run(outputBiases))
Printing the code should give an effect similar to this:
('Input wages: ', array([[ -6.69970608, 5.47385073],
[ 6.81709385, -5.15285587]], dtype=float32))
('Input biases: ', array([ 3.46804953, 2.56963539 ], dtype=float32))
('Output wages: ', array([[ -6.58759022],
[ -6.7153616]], dtype=float32))
('Output biases: ', array([ 9.69208241], dtype=float32))
Looks like our network is trained, we have all the weights and biases we need. Now it’s time to verify that it’s working properly.
5. Running
To run the trained neural network in Swift we will use the BNNS framework provided by Apple.
BNNS – Basic Neural Network Subroutines is a collection of functions that you use to implement and run neural networks, using previously obtained training data. It is supported in macOS, iOS, tvOS, and watchOS, and is optimized for all CPUs supported on those platforms.
import Accelerate private var inputFilter: BNNSFilter? private var outputFilter: BNNSFilter? let inputWeights: [Float] = [ -6.69970608, 5.47385073, 6.81709385, -5.15285587 ] let inputBiases: [Float] = [ 3.46804953, 2.56963539] let outputWeights: [Float] = [-6.58759022, -6.7153616 ] let outputBiases: [Float] = [ 9.69208241 ]
At first, we import Accelerate, a framework which contains BNNS. Why are the variables of BNNSFilter type? As you might have noticed in section 3, nothing really happens in neurons, as they are only data storage, instead all calculations take place between particular layers. In BNNS we work on filters, a kind of “layer for calculations”. Later we define the weights received from TensorFlow.
let activation = BNNSActivation(function: BNNSActivationFunctionSigmoid, alpha: 0, beta: 0)
In the next step we define the activation object, once again (as in TensorFlow) we use the sigmoid function. Next we have to define 2 filters, which calculate data between our 3 layers:
//1st filter
let inputToHiddenWeightsData = BNNSLayerData(
data: inputWeights, data_type: BNNSDataTypeFloat32,
data_scale: 0, data_bias: 0, data_table: nil)
let inputToHiddenBiasData = BNNSLayerData(
data: inputBiases, data_type: BNNSDataTypeFloat32,
data_scale: 0, data_bias: 0, data_table: nil)
var inputToHiddenParams = BNNSFullyConnectedLayerParameters(
in_size: 2, out_size: 2, weights: inputToHiddenWeightsData,
bias: inputToHiddenBiasData, activation: activation)
var inputDescriptor = BNNSVectorDescriptor(
size: 2, data_type: BNNSDataTypeFloat32, data_scale: 0, data_bias: 0)
var hiddenDescriptor = BNNSVectorDescriptor(
size: 2, data_type: BNNSDataTypeFloat32, data_scale: 0, data_bias: 0)
inputFilter = BNNSFilterCreateFullyConnectedLayer(&inputDescriptor, &hiddenDescriptor, &inputToHiddenParams, nil)
guard (inputFilter != nil) else {
return
}
//2nd filter
let hiddenToOutputWeightsData = BNNSLayerData(
data:outputWeights, data_type: BNNSDataTypeFloat32,
data_scale: 0, data_bias: 0, data_table: nil)
let hiddenToOutputBiasData = BNNSLayerData(
data: outputBiases, data_type: BNNSDataTypeFloat32,
data_scale: 0, data_bias: 0, data_table: nil)
var hiddenToOutputParams = BNNSFullyConnectedLayerParameters(
in_size: 2, out_size: 1, weights: hiddenToOutputWeightsData,
bias: hiddenToOutputBiasData, activation: activation)
var outputDescriptor = BNNSVectorDescriptor(
size: 1, data_type: BNNSDataTypeFloat32, data_scale: 0, data_bias: 0)
outputFilter = BNNSFilterCreateFullyConnectedLayer(&hiddenDescriptor, &outputDescriptor, &hiddenToOutputParams, nil)
guard (outputFilter != nil) else {
return
}
I strongly believe that the names of the variables are pretty self-explanatory. When both layers are defined, it’s time to create a testing method:
func testNetwork(_ input: [Float]) {
var hidden: [Float] = [0, 0]
var output: [Float] = [0]
//@return 0 on success, and -1 on failure.
if BNNSFilterApply(inputFilter, input, &hidden) != 0 {
print("Hidden Layer failed.")
return
}
if BNNSFilterApply(outputFilter, hidden, &output) != 0 {
print("Output Layer failed.")
return
}
print("Testing [(input)] = (output[0])")
}
The above method receives testing data in the form of an array, then defines 2 empty arrays, so they can be used by inputFilter and outputFilter. The next 2 operations use defined filters to count values for hidden and output neurons. With this part ready, we can test our newly created network:
testNetwork([0, 0]) testNetwork([0, 1]) testNetwork([1, 0]) testNetwork([1, 1])
The last step is to clean the memory by deallocating the filters we created:
BNNSFilterDestroy(inputFilter) BNNSFilterDestroy(outputFilter)
This is it, the result of running the Swift code should look somewhat similar to this:
Testing [[0.0, 0.0]] = 0.050493 Testing [[0.0, 1.0]] = 0.933003 Testing [[1.0, 0.0]] = 0.938602 Testing [[1.0, 1.0]] = 0.0530334
It’s worth remembering that the sigmoid function never reaches -1 and 1, but as the above logs show, our network is able to solve the XOR function in a proper way, longer training will take the results closer to 1 or 0.
Summary
So this is it, we designed, trained and ran our first neural network. I strongly believe that this code will help you to understand what this process looks like in the real world. Maybe it will be a starting point in our further journey into the awesome world of machine learning 🙂