Computer Networking: a Primer

It is impossible to know everything in this industry. Unlike the early days of computing, with pioneers like Steve Wozniak engineering everything from the operating system down to the circuit boards, we now have layers upon layers of abstraction – layers that naturally lead to specialization. One person may know JavaScript inside and out yet be stumped by setting up a server, while another may know how configure large networks but have no idea how to build a web app.
The interesting (and challenging) thing about working for a consulting company is the need to grasp not only the technical side of a project, but also the subject matter. I was sitting comfortably in the front-end side of the spectrum until taking on a project for which understanding computer networking is necessary domain knowledge. Having taken a non-traditional path into programming, networking terminology was not in my lexicon. Luckily, there is a MOOC for everything these days, and this course from Stanford Online is helping me fill in the gaps.
Before the course, I found it difficult to look up my networking questions because I did not have enough of a mental framework in which to place the new concepts. So, for those of us who are more comfortable with CSS than CIDRs, here is part one of a broad-brush, glossary-esque overview of the basics of computer networking.
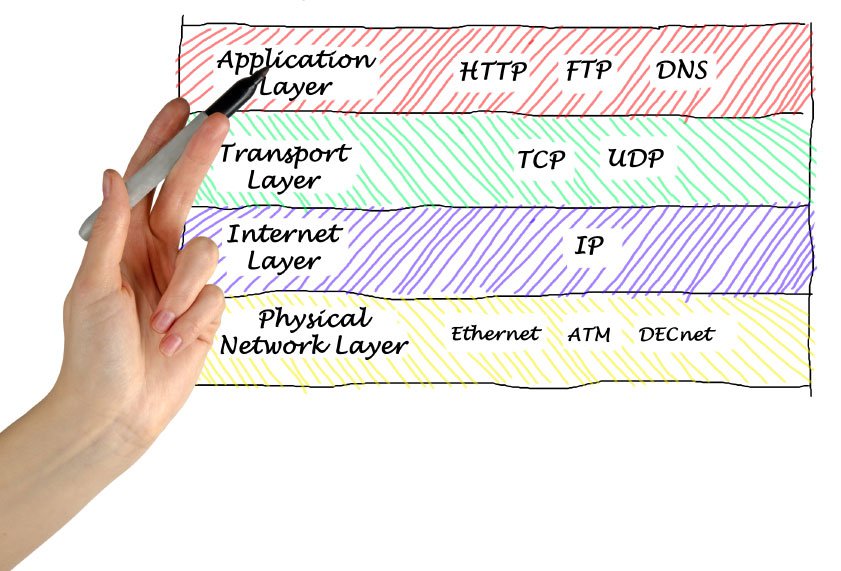
The Four-Layer Model
The internet can be thought of in four layers: application, transport, network, and link layers. Each layer operates independently and provides a specific service for the layer above it. Information is passed from layer to layer in packets, self-contained units of data with a header containing the information needed get itself to its destination. Data is shared between layers in a manner that brings to mind nested Russian dolls: each layer will encapsulate the packet it receives with its own header containing information specific to that layer’s duties. Upon reaching the destination, the packets are opened, layer by layer, until the original request can be processed by the destination application.
The Application Layer
Let’s start at the top. The application layer declares how two computers communicate with each other. The choice of protocol depends on the goal of the communication. The World Wide Web uses HTTP (Hypertext Transfer Protocol) as the agreed-upon means of communication, but there are dozens of other protocols: sending and receiving email, for example, would require using SMTP (Simple Mail Transfer Protocol), while running remote commands on another computer would use SSH (Secure Shell) protocol.
HTTP is the request/response protocol that our browser applications use to communicate with the server on the other end. When browsing the web, your computer uses HTTP to make a request to the server (to GET a webpage or POST the data we’re submitting in a form, for example). Before your request can reach the server on the other end, though, it needs to go down through the layers.
The Transport Layer
An application can choose how to address issues like reliability by selecting an appropriate transport protocol. The most commonly used protocols are TCP (Transmission Control Protocol, used by 95% of applications), UDP (User Datagram Protocol – fast, but unreliable), and ICMP (Internet Control Message Protocol, which is used to diagnose network problems – ping, for example, uses ICMP).
Because TCP is the most widely used transport protocol, it is worth looking at in more detail. TCP can be thought of as your most type-A coworker – let’s say, oh, Tivix project manager Amber Chang. The network layer below might be handing up to the transport layer packets that are incomplete or out of order, but when information is handed over to TCP/Amber, it makes darn well sure that the information is correct and complete, gets to where it needs to go in a timely fashion, and is re-done when necessary.
TCP keeps state to keep tabs on how the layers below are doing. This state is known as a “three-way handshake”: When Computer A wants to connect with Computer B, it sends a Synchronization request. Computer B responds, Acknowledging that request, and sending a Syn request of its own. Computer A responds with an Ack. After this exchange is complete, a connection is in place for the two computers to send packets back and forth until the connection is closed. The computers will continue to acknowledge when packets are received, which makes it possible for TCP to detect when a packet has been dropped and needs to be re-transmitted.
The process of acknowledging the receipt of packets also makes it possible for TCP to implement flow control: making sure that data isn’t being sent faster than the receiver can handle, which would result in dropped packets. For speed, we want to have multiple packets traveling at one time (rather than having to wait for the server to send back an Ack before sending another packet), but how many packets are too many? The TCP header contains a window, or a maximum number of packets that the receiver will accept. This window expands as packets are accepted, and is dropped in half when packets start getting dropped – a process called AIMD (Additive Increase, Multiplicative Decrease).
The Network Layer (a.k.a. the Internet Layer)
If TCP is your type-A coworker, IP (Internet Protocol) is that friend who is generally a good guy, yet you wouldn’t trust him to feed your pets while you’re out of town due to the small (but very real) chance you’d return to find them dead. The network layer must use IP, and IP’s only job is to get packets from Point A to Point B. It can usually can get the job done (that’s why you’re still friends), but it makes no guarantees, and it doesn’t bother to alert anyone if something goes awry. Packets may arrive at the destination out of order, or they may get lost along the way. That’s why most applications use TCP in the transport layer above, adding a level of reliability that IP does not provide.
To get packets to their destination, the network layer uses unique IP addresses. IP addresses are written in four sets of 32 bits (e.g. 120.120.120.120). IP addresses are structured by CIDR (Classless Inter-Domain Routing), which gives flexibility in breaking an IP address down into subnets of appropriate sizes. If a CIDR is /16, it means that 16 bits are used up for network identification, while the rest is available to be used for specific computers. A net mask tells you which IP addresses are local to your network and which will require going out through a router. For example, if a net mask is 255.255.0.0, the first 16 bits of two IP addresses must match in order for them to be in the same network.
The Link Layer (the Physical Network Layer)
So, we’re sending packets out into the world, stamped with a destination address but no map showing the packet how to get there. The packet will make its way to its destination through a process called packet switching. This happens at the link layer, which consists of routers and the links connecting them. A packet is passed along, “hop by hop,” until reaching its destination.
When the packet arrives at a router, the router looks at a forwarding table to find the address closest to the destination address, and sends the packet on its merry way to the next router. A router’s forwarding table may have multiple options for where the packet should be sent, so the link layer uses Longest Prefix Match to determine which address to send a packet to next. Longest Prefix Match looks for the biggest CIDR, which suggests that a larger number of bits in the address match up with the destination address for your packet. ARP (Address Resolution Protocol) maps addresses to bridges the gap between the IP address and the address of the physical link the packet needs reach.
While I won’t be running out to study for Cisco certification any time soon, learning about networking has certainly has given me a better understanding of and appreciation for what happens “under the hood.” I’m still learning, and will return with part two after finishing the course.